前言
看过一段时间tensorflow的教程,看代码能知个大概,也算入了门。当时学的时候发现最蛋疼的就是如何调输入数据的格式了。自学能力差到一定的极致,就是看了几天教程这一个问题还是没得到解决。但是我还是对A1课程上的手写识别做了简单的训练预测。代表我入门过。(仅仅是入门,代码简单大神再见)
简介
使用 TensorFlow, 你必须明白 TensorFlow:
- 使用图 (graph) 来表示计算任务.
- 在被称之为 会话 (Session) 的上下文 (context) 中执行图.
- 使用 tensor 表示数据.
- 通过 变量 (Variable) 维护状态.
- 使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据.
从我个人理解出发,tensorflow的框架使用也大致分为三个部分:网络结构定义,数据格式调整及输入,数据预测。python只是tensorflow的一个数据输入接口,实际做训练预测都是通过C语言来实现的,这是为了提高速度和效率。接下来就分这三个模块介绍下我的代码。
网络结构定义
代码如下:
|
|
数据格式调整及输入
代码如下:
|
|
数据预测
代码如下:
|
|
结果显示
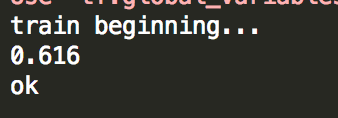
因为使用了最简单的网络,重点在于入门,所以准确率很低,才61%,也无伤大雅吧(尴尬的笑)。