前言
在自定义网络模型实现图像识别中介绍了caffe的基本用法,关于caffe的介绍在此不再赘述。
介绍这篇文章之前首先特别感谢夏天大神的指导交流。这篇文章中使用了caffe的python接口,数据为数组元素而非图像,依然有参考价值。
数据输入
数据如下显示: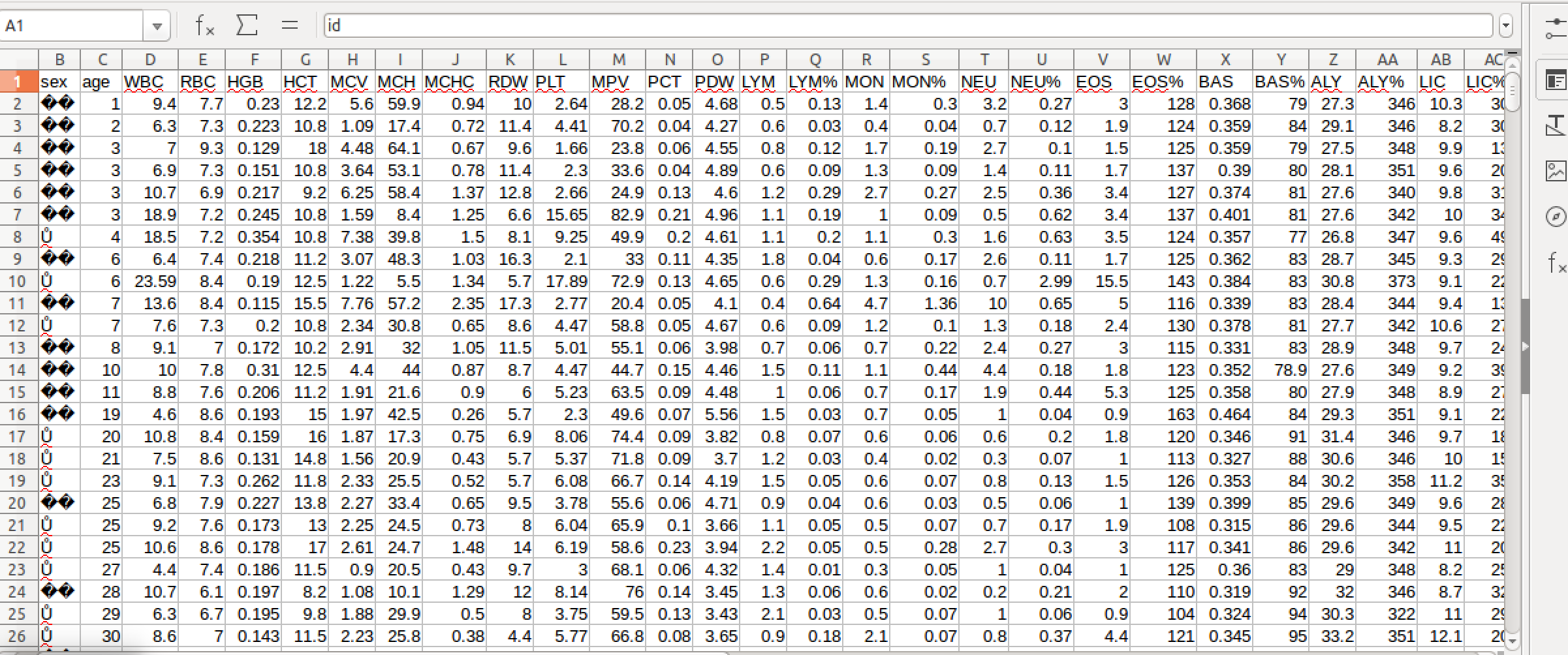
数据转换代码如下所示
|
|
关于以上代码的几点说明:
- 使用numpy工具以矩阵形式读入csv数据文件,因为性别为string类型,需要将其转换成int类型;
- 为了提高准确度,夏天大神写了一个nomalize函数对数据进行了归一化处理,而我就在对数据向量化处理时对数据做log运算操作
vec_log = np.vectorize(lambda x: math.log(x+1)) - 其他细节可以看上面代码注释,整体来说还是通俗易懂的。
训练及预测
训练和预测的python代码很简单,如下所示:
|
|
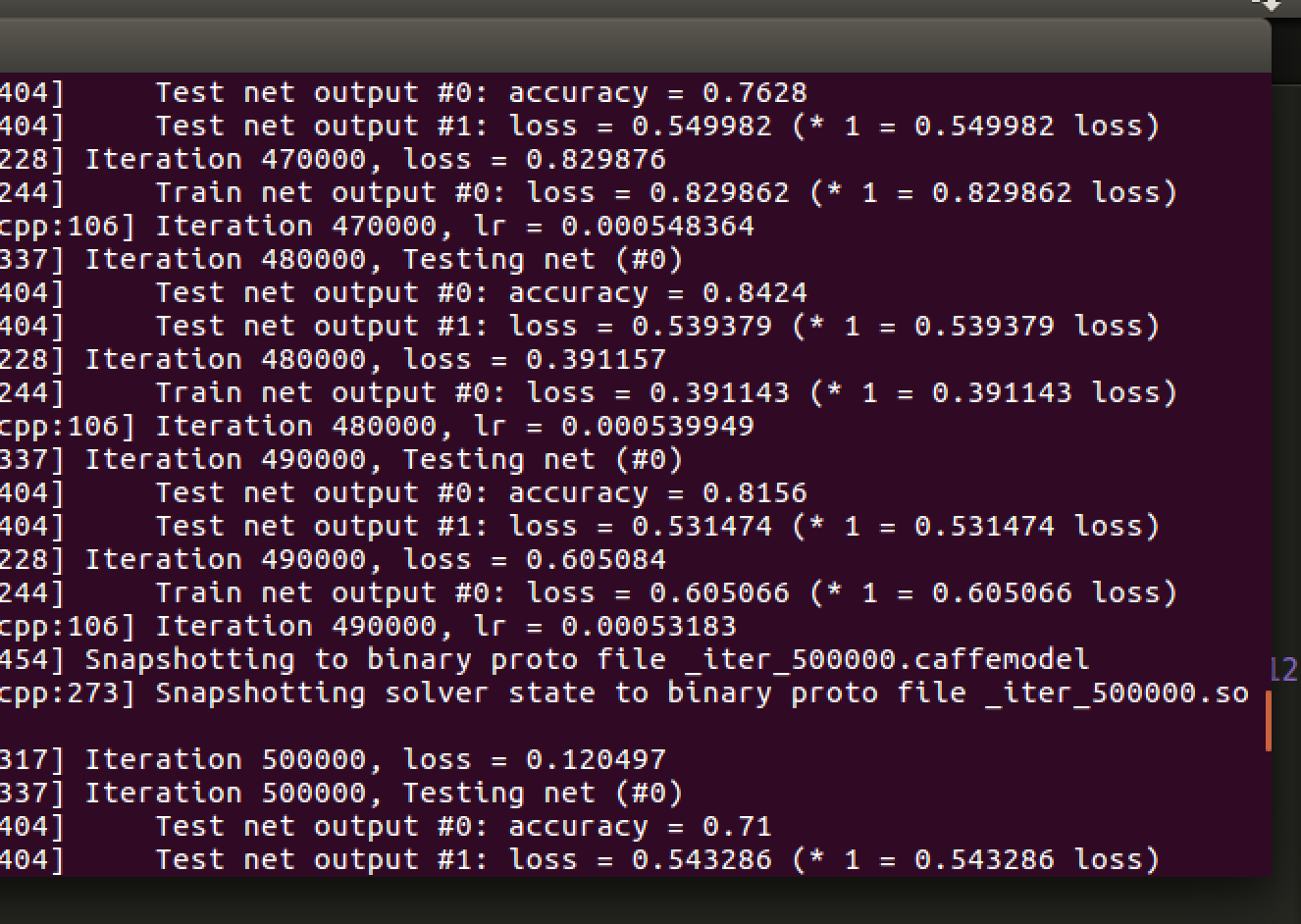
网络模型定义了两个全连接层,relu激发函数,学习率变化策略使用了inv,数据较少,迭代次数都调到上万。训练时准确度到过80+,实际预测准确度最终达到71%。
结果如下所示: